InternImage:Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
摘要
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs.
作者认为,现如今CNN网络与主流的Vit框架的差距主要在于两个方面:
- 多头自注意力机制具有长程依赖性和自适应空间聚集性,vit会比cnn在大量数据上学习到更加强大且鲁棒性高的数据表示。
- 从架构角度来说,Vit含有许多CNN不具备的高级组件,如LayerNormalization,FFN ,GELU等。
Method
为了设计一个大规模的CNN网络模型,作者使用一个灵活的卷积变体,命名为DCNv2,并且为其进行了调整以更好适应大规模模型。接着,作者将基本模块与在现如今架构中先进的模块设计结合,最后作者探索了基于DCN的块的堆叠和缩放原理,以构建能够从海量数据中学习强表示的大规模卷积模型。
Deformable Convolution v3
之前的工作[ 21、22、50]已经广泛讨论了CNNs和ViTs的区别。在确定Intern Image的核心算子之前,作者首先总结了正则卷积和MHSA的主要区别。
- 长程依赖:尽管人们早已认识到具有较大有效感受野(长程依赖)的模型通常在下游视觉任务上表现更好,但是33的规则卷积核的实际感受野较小,即使是非常深的模型基于CNN的模型也无法获得vit的长程依赖,这限制了他的性能。
- 自适应空间聚集:自适应空间聚合是指模型在处理视觉信息时,能够根据输入数据的特征和任务需求,动态调整对不同空间位置信息的聚合方式,而非采用固定的规则。常规卷积是一种具有静态权重和强归纳偏置的算子,例如二维局部性、邻域结构、平移不变性等。这高度归纳的特性使得常规卷积组成的模型可能比vit收敛的更快,所需要的训练数据更少,但也限制了卷积神经网络从大规模数据中学习到更加通用,具有鲁棒性的能力。
弥合卷积和MHSA之间鸿沟的一个简单方法是在正则卷积中引入长程依赖和自适应空间聚合。
可变形卷积 v2(DCNv2)正是这样一种改进的卷积算子,它通过灵活调整采样位置和权重,成为连接卷积与 MHSA 的关键一步。
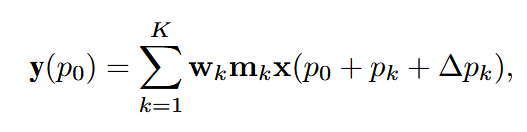

输入特征图:x 是维度为 (\mathbb{R}^{C \times H \times W}) 的特征图,其中 C 为通道数,(H \times W) 为空间尺寸。
当前像素位置:(p_0 = (i, j)) 表示输出特征图中当前像素的坐标(如二维图像中的行和列)。
采样位置计算:(p_0 + p_k + Delta p_k)
表示输入特征图中实际采样点的坐标,其中:
- pk是预定义的固定网格偏移(如 3×3 卷积的 9 个基础位置,如 (p_1 = (-1, -1)) 对应左上角);
- 是可学习的动态偏移量(如通过训练得到的额外偏移,允许采样点 “变形”)。
在传统应用中,DCNv2 通常作为常规卷积的 “插件” 使用,依赖预训练权重(如 ImageNet 预训练的 ResNet 权重)进行微调:
- 参数与内存复杂度高:原始 DCNv2 中每个卷积神经元(如 3×3 卷积的 9 个采样点)拥有独立的投影权重 (w_k \in \mathbb{R}^{C \times C}),参数总量与采样点数量呈线性关系(如 C=256 时,9 个采样点的权重参数达 (9 \times 256 \times 256 = 589,824)),在大规模模型中(如 10 亿参数)会导致内存爆炸。
- 训练策略依赖预训练:常规 DCNv2 通过加载预训练权重初始化,再微调优化,这种方式适用于中小规模模型,但大规模基础模型(如需要从 4 亿图像中从头训练)难以依赖预训练,需独立学习参数。
- 稳定性问题:原始 DCNv2 中调制标量 (m_k) 使用 Sigmoid 归一化,其和不固定(范围 0 到 K),在大规模数据训练时易导致梯度不稳定,尤其当模型深度和宽度增加时,优化难度显著上升。
作者对DCNv2进行改进以使其适用于大规模训练,主要优化如下:
Sharing weights among convolutional neurons.将wk分解为深度-wise部分和点-wise部分,其中深度部分由mk替代,点部分由所有采样点共享一组投影权重w

Introducing multi-group mechanism.作者受到多头注意力机制的启发,将空间聚合过程拆分为G个组,每个组具有单独的采样偏移量∆pgk和调制尺度mgk,因此单个卷积层上的不同组可以具有不同的空间聚合模式,从而为下游任务提供更强的特征。得到DCN v3
v3的三个优点:
- 弥补了卷积网络对长程依赖和适应性空间聚集的不足
- 与多头自注意力相比更加节省内存和训练时间
- 该算子基于稀疏采样,比之前的方法如MHSA和重新参数化大核等具有更高的计算和内存效率。
InternImage Model
基础模块搭建:与传统的CNN网络不同,internimage的模块设计更加接近于Vit模型,装配了更加先进的组件,包括LN,FFN前馈网络,GELU等
采样偏置和调制尺度通过可分离卷积输入特征x来决定
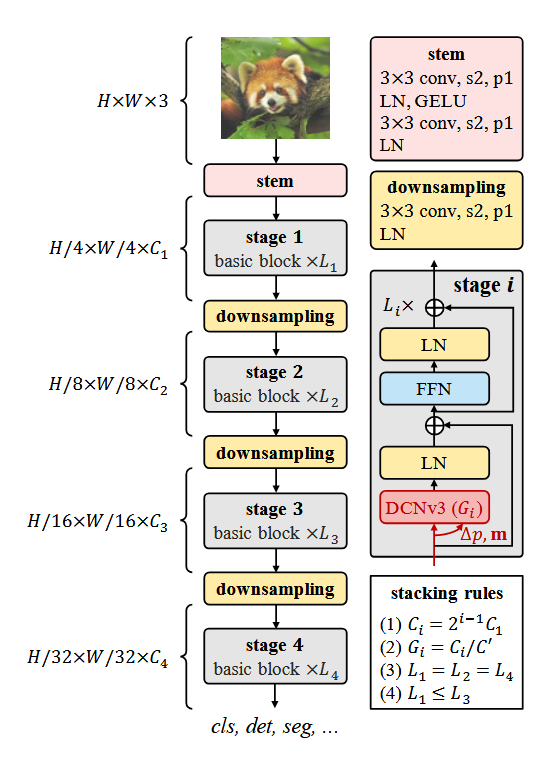
Stem & downsampling layers:为了获得层次化的特征图,使用卷积主干和下采样层将特征图调整到不同的尺度。stem层将输入分辨率缩小四倍,stem设计如下:
下采样模块设计:
堆叠方式:采用四阶段堆叠,堆叠规则可概括为以下四点:
- 通道数堆叠规则:第i阶段的通道数(C_i)由第 1 阶段通道数(C_1)决定,遵循指数递增,通过指数级通道数增长,匹配视觉任务中特征图分辨率递减的需求
- stage1:C1
- stage2:2*C1
- stage3:4*C1
- stage4:8*C1
- 分组数与通道数关联:

- 模块数遵循AABA分布:

- 超参数降维
