SegNeXt:Rethinking Convolutional Attention Design for Semantic Segmentation
SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
摘要
We present SegNeXt, a simple convolutional network architecture for semantic segmentation. Recent transformer-based models have dominated the field of semantic segmentation due to the efficiency of self-attention in encoding spatial information. In this paper, we show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, we discover several key components leading to the performance improvement of segmentation models. This motivates us to design a novel convolutional attention network that uses cheap convolutional operations. Without bells and whistles, our SegNeXt significantly improves the performance of previous state-of-the-art methods on popular benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID. Notably, SegNeXt outperforms EfficientNet-L2 w/ NAS-FPN and achieves 90.6% mIoU on the Pascal VOC 2012 test leaderboard using only 1/10 parameters of it. On average, SegNeXt achieves about 2.0% mIoU improvements compared to the state-of-the-art methods on the ADE20K datasets with the same or fewer computations. Code is available.
Method
卷积encoder
使用MSCA来替代原本的注意力机制encoder,主要分为三个部分:
- 深度卷积来提取局部信息
- 多分支深度卷积来捕获多尺度上下文
- 1X1卷积来建模不同通道的关系
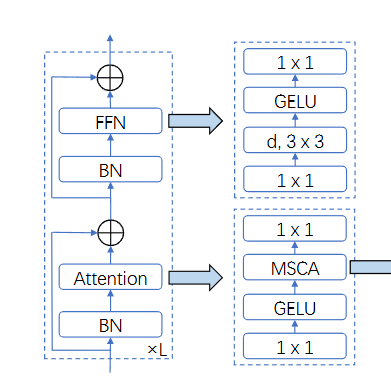
1x1卷积的输出被当作注意力权重来直接和输入相乘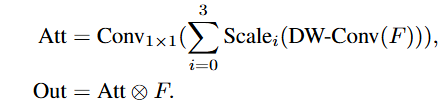
Att和模型的输入进行元素级别的相乘
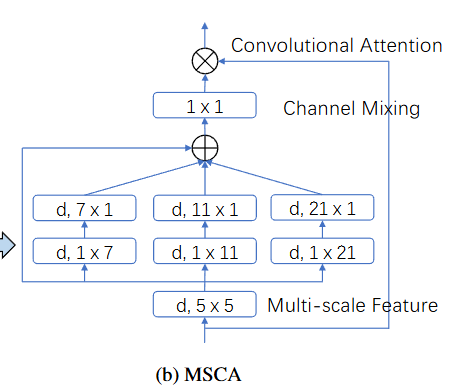
将一系列的块进行堆叠就形成了论文提出的卷积编码器MSCAN
采用等级制度结构,包含了四个递减的空间分辨率,H/4 × W/4 , H/8 × W/8 , H/16 × W/16 和 H/32 × W/32
每个阶段都包含了一个下采样模块
Decoder
三种解码器可以选择:
- segformer 解码器,纯MLP
- 直接输入到解码头
- 从最后三个阶段聚合特征,并使用轻量级Hamburger[21]进一步建模全局上下文。结合我们强大的卷积编码器,我们发现使用轻量级解码器可以提高性能计算效率。这也是论文所采用的解码器模式