决策树模型
斯坦福吴恩达2022机器学习
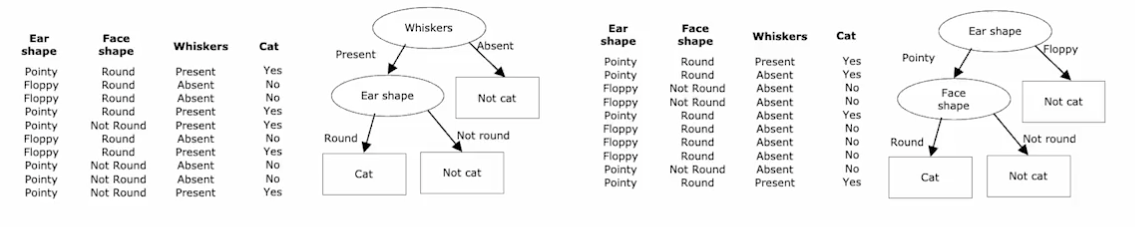
简单的决策树模型
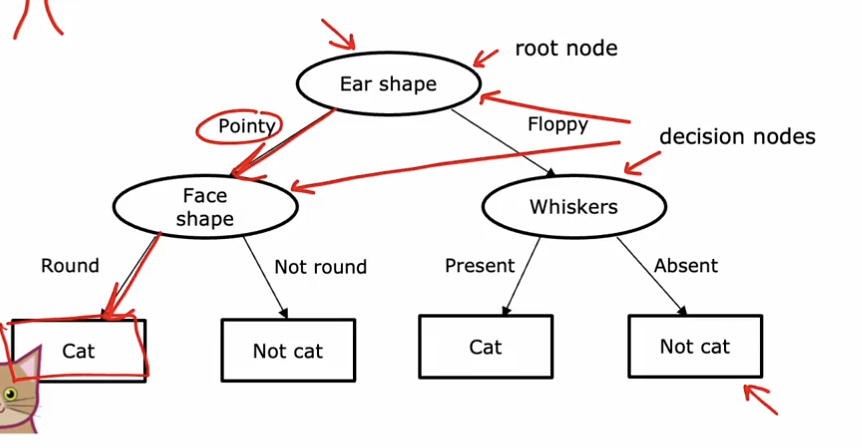
类似于完全二叉树,有根节点和叶节点
模型建立的两个关键点:
- 如何决定分割的特征?
- 如何判断叶节点的分类结果好坏?
纯度测量
用熵来作为纯度的度量
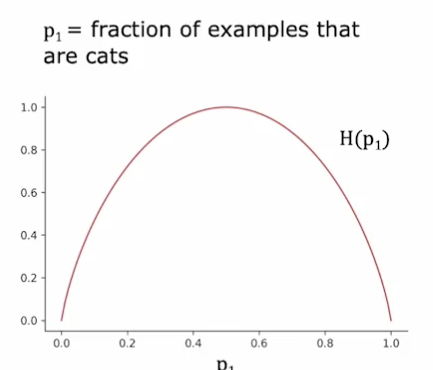

当结点中的样本全为猫时,p1=1,此时熵的值为0,当样本中全为狗时同理
当结点中的样本为一半猫一半狗时,p1=0.5,此时熵最高为1
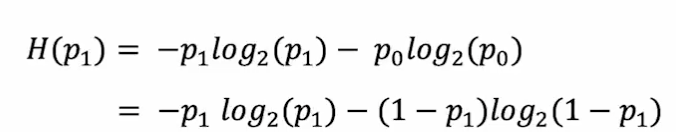
在p=0的情形中,log(0)是无法计算的,那么我们需要提前约定0log(0)=0,才能正确计算熵
选择分离的特征
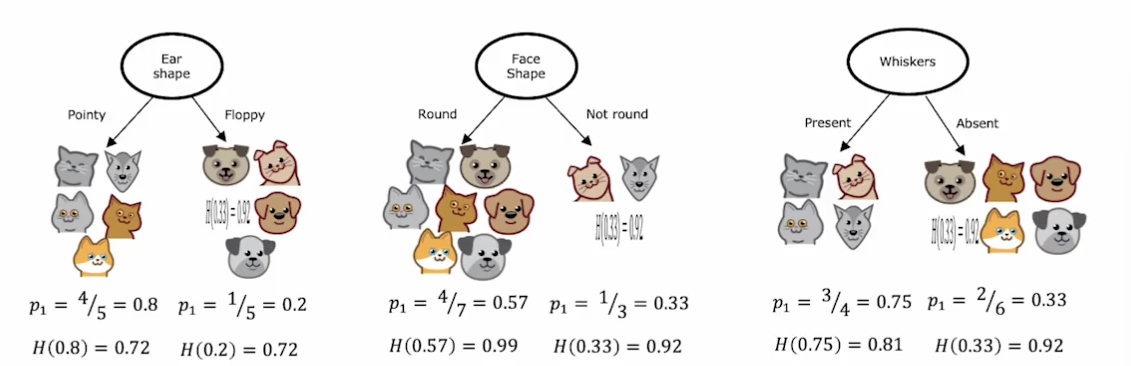
在上图中,每个特征筛选出来的分支都有各自的纯度熵,那么如何根据这些熵来判断哪个特征分类情况最好呢?我们使用每个特征的熵的加权平均来作为评估方式。
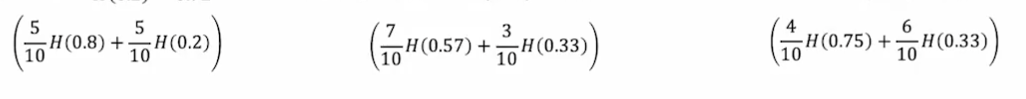
在耳朵形状这一特征中,五个样本被分到了立耳,五个样本被分到了塌耳,那么则可通过上图公式1来进行加权平均计算出式子2
根节点的熵为H(5/10)=1,因为根节点在用特征分类前是十个样本,其中五个样本是猫。
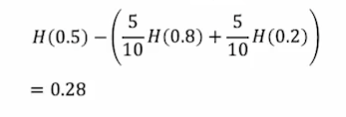
最后的评估指标等于根节点的熵减去式子2得到熵的减少,即拆分信息增益,分类特征2和3同理,选择熵的减少量最大的特征。

随机森林算法
有随机抽样的样本来构建不同的树构成森林
For b=1 to B:
Use sampling with replacement to create a new training set of size m Train a decision tree on the new dataset
信息增熵
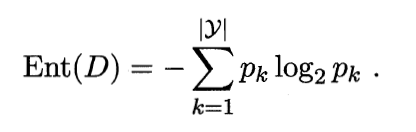 信息熵的计算公式
信息熵的计算公式
pk为当前样本集合D中第k类样本所占的比例
信息熵的值越小则D的纯度越高

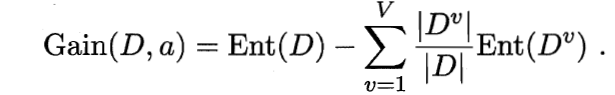
信息增益越大,则样本在该属性下的纯度提升越大,属性选择更好
信息增益准则对取值较多的属性有所偏好,仅仅采用增益来选取合适的属性会导致决策树的泛化能力很差
增益率
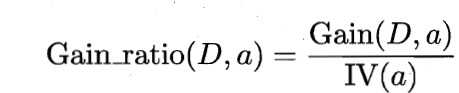
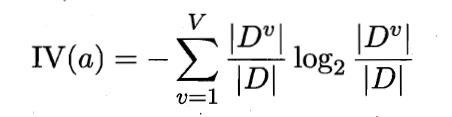 为属性a的固有值
为属性a的固有值
属性a的取值数目越多则固有值越大
增益率对取值可能较少的属性有所偏好,在C4.5算法中并不是直接取增益率最大的候选划分属性,而是使用了启发式:先从候选属性中选择信息增益高于平均水平的属性集合,再从该集合中选择增益率最高的属性
CART决策树
classification and regression tree 分类和回归都可用
使用基尼指数来选择划分属性
数据集D的纯度可用基尼值来度量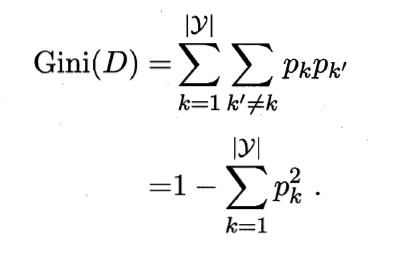
Gini反应了从数据集D中随机抽取两个样本其类别标记不一样的概率
属性a的基尼指数定义为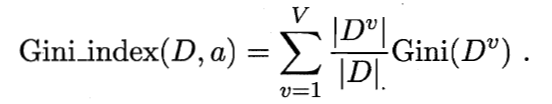
选择基尼指数最小的属性