数据集的误差指标与权衡
课程是斯坦福吴恩达2022机器学习
交叉验证集的预测误差指标
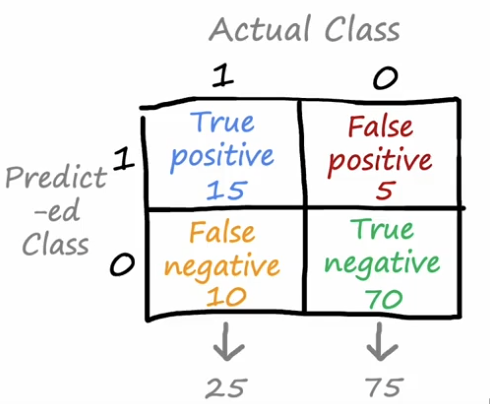
- TP:True Positive预测的分类和实际分类相符且均为正例
- TN:True Negative预测的分类和实际分类相符且均为负例
- FP:False Negative预测的分类和实际分类不符,且预测的是正例
- FN:False Negative预测的分类和实际分类不符,且预测的是负例
预测精确度的计算:

对于精确度我们可以理解为,假设在病人预测中,我们用模型预测的有病的个体中,实际真的患病的人占预测有病的人数的多少,也就是我们模型的预测正例正确的样本数占预测为正例的样本数的多少。
Recall指标:

recall指标可以理解为在所有确实患病的样本中,我们的模型正确预测出了多少样本,即预测正例且正确的样本数占实际为正例的样本数的多少。
精确度和recall之间的权衡

假设在病人患病预测中,我们使用罗杰斯蒂回归来预测病人患病的概率,函数返回值大于0.5则预测为正例,若函数返回值小于0.5则预测为负例。但如果患病的话会接受非常痛苦且昂贵的治疗,且患病不治疗的后果并没有那么严重,那么我们可以想要让模型在预测为正例时更加谨慎些,即提高阈值到0.7。
在提高阈值之后,我们在模型预测为正例的样本中,实际患病的样本数占正例样本更多了,因为我们预测的非常谨慎,那么预测中真的患病的人数也会占更多数,此时我们的精确率会提高。但是相反的,在所有真正患病的样本中,我们预测的患病人数占的比例也少了,recall指标会下降。
同样,如果假设患病治疗费用和代价很低,但不治疗后果严重,那么我们希望模型在预测患病时没那么严谨,来保证更多的病人被正确预测出疾病,那么就可以降低阈值,此时精确度降低但recall升高。
F1 score
如何让模型自动选择合适的权衡?
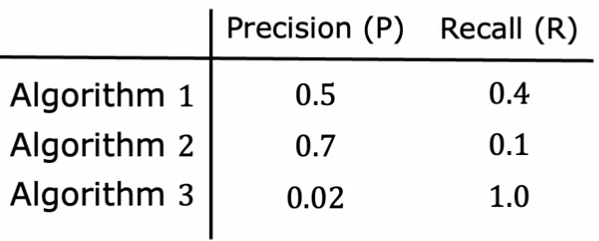
在这三个算法中,各有优点很难根据精确度和recall评判哪个是最优的算法,这时就需要F1Score帮助
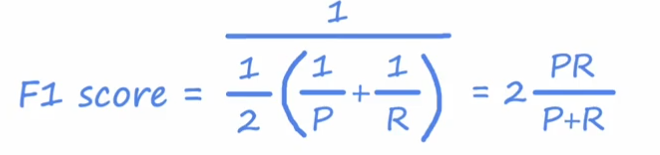
F1Score更高的算法会被选择