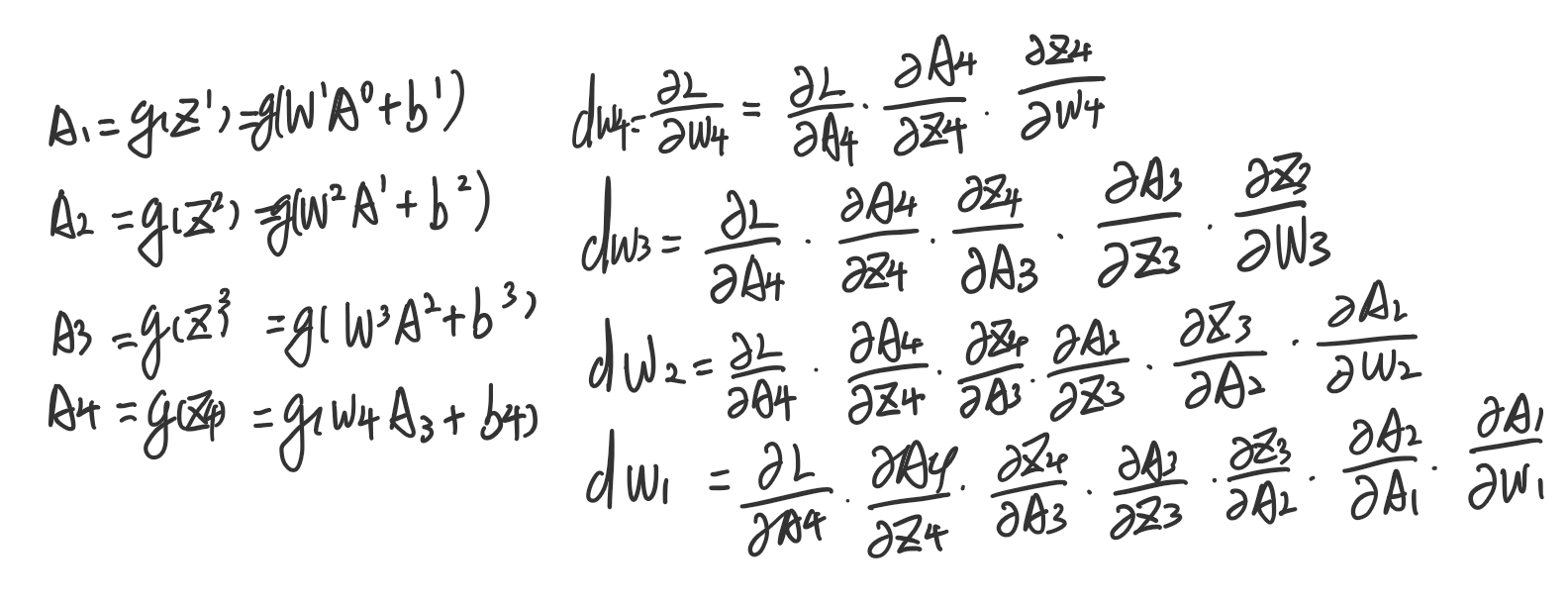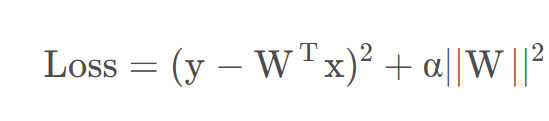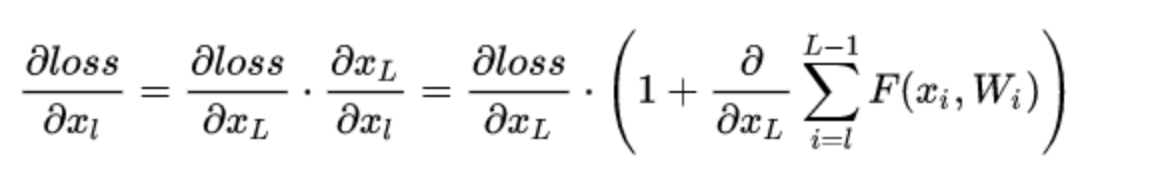课程是b站刘二大人的课,算是速成吧,基础知识不是很多,专注于应用,中间不懂得可以再补
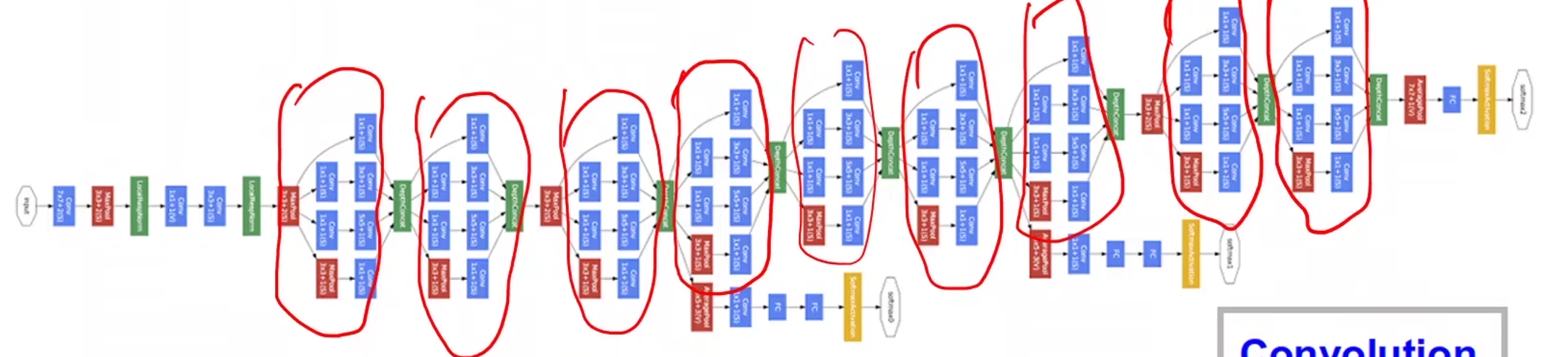
GoogleNet
Inception Module 上图的Inception模型是GoogleNet模型中的小块,红色圈中即为Inception
Concatenate将每一路径得到的张量拼接成一个张量
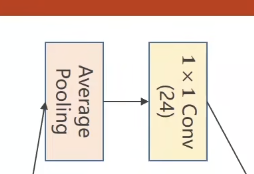
在进行Average Pooling池化时,可以进行相应的padding和stride来保证张量的w和h不会改变
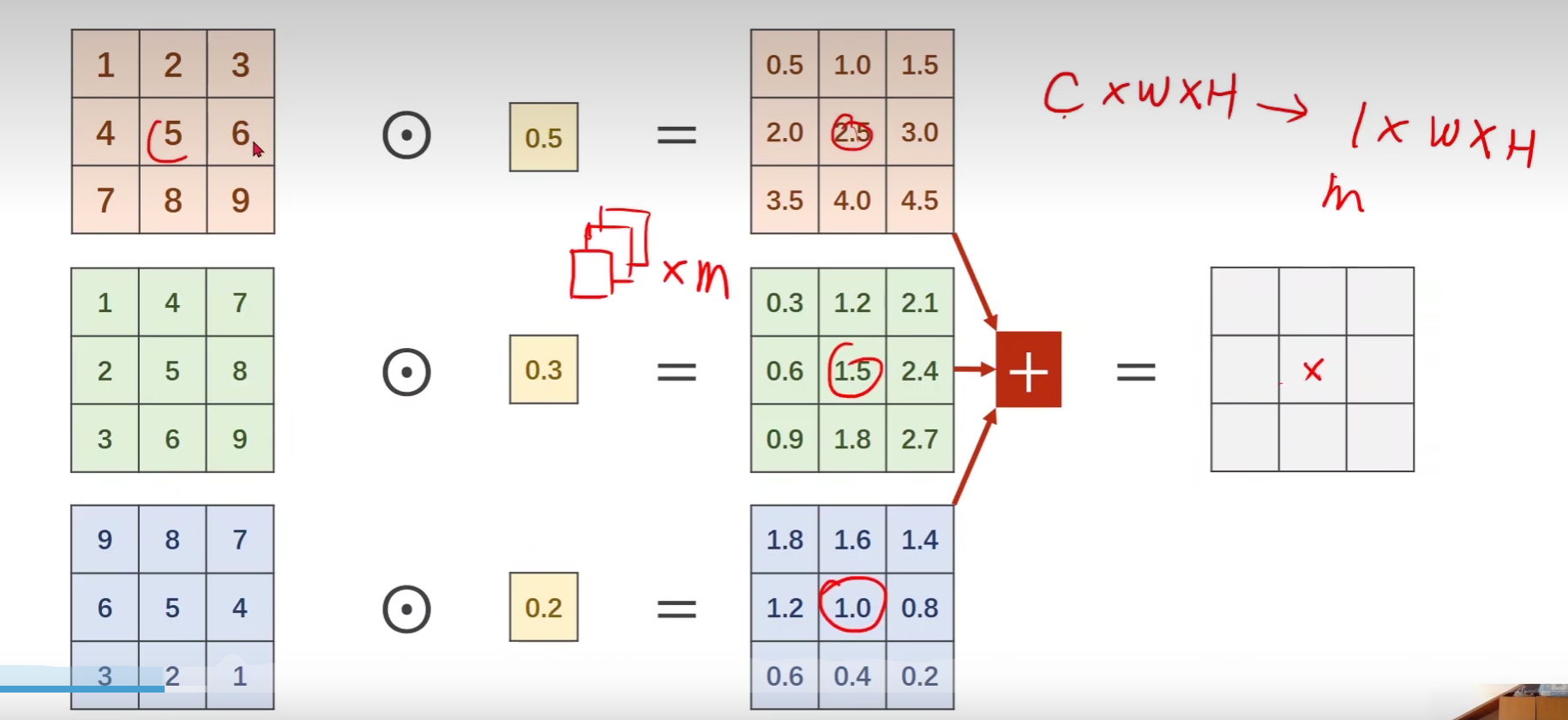
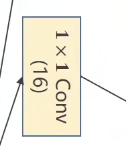
1*1卷积核的作用是什么? 在1*1卷积核中,我们可以对不同通道的相同位置的像素值进行计算并加和,有此将CxWxH的张量转化为1xWxH的张量,实现降通道操作,具体图示如下:
为什么需要1*1的卷积核? 可以对图像数据进行降通道的操作,在卷积运算中显著的减少运算量
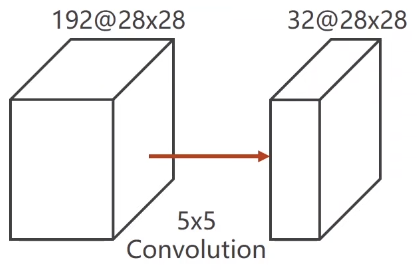
再上图的卷积运算中,我们将192x28x28的数据卷积成32x28x28的数据,需要进行的运算操作数为
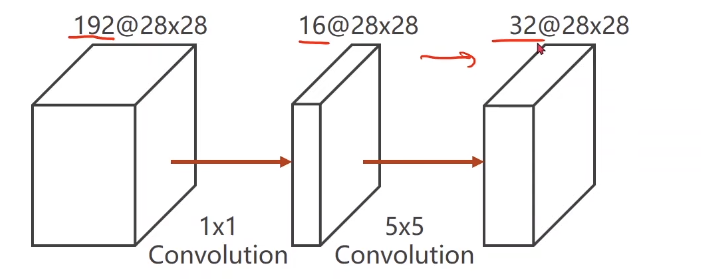
如果先对原数据进行1*1的卷积降低通道数,再进行5x5卷积,所需的运算操作数为由此可见运算操作数明显减少
代码实现及注释
池化层对应代码如下:
1 2 3 4 self .branch_pool = torch.nn.Conv2d(in_channels, 24 , kernel_size=1 )branch_pool = F.avg_pool2d(x, kernel_size=3 , stride=1 , padding=1 ) branch_pool = self .branch_pool(branch_pool)
1x1卷积层对应代码如下:
1 2 3 self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) branch1x1 = self.branch1x1(x)
5x5卷积层对应代码如下:
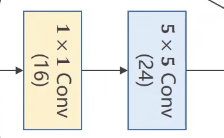
1 2 3 4 5 self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2) branch5x5 = self.branch5x5_1(x) branch5x5 = self.branch5x5_2(branch5x5)
3x3卷积层对应代码如下:
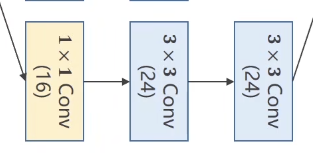
1 2 3 4 5 6 7 self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1) self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1) branch3x3 = self.branch3x3_1(x) branch3x3 = self.branch3x3_2(branch3x3) branch3x3 = self.branch3x3_3(branch3x3)
最后对每一块得到的卷积张量在通道维度进行合并形成新的张量
1 2 outputs = [branch1x1, branch3x3, branch5x5, branch_pool] return torch.cat(outputs, dim=1) # 将卷积结果按照通道维度进行拼接
dim指定在某一维度进行合并张量,包含(batch,通道,宽,高)四个维度
总体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class InceptionA(torch.nn.Module): def __init__(self, in_channels): super(InceptionA, self).__init__() # 1x1块 self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) # 5x5块 self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2) # 3x3块 self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1) self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1) # 池化块 self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1) def forward(self, x): branch1x1 = self.branch1x1(x) branch5x5 = self.branch5x5_1(x) branch5x5 = self.branch5x5_2(branch5x5) branch3x3 = self.branch3x3_1(x) branch3x3 = self.branch3x3_2(branch3x3) branch3x3 = self.branch3x3_3(branch3x3) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch3x3, branch5x5, branch_pool] return torch.cat(outputs, dim=1) # 将卷积结果按照通道维度进行拼接
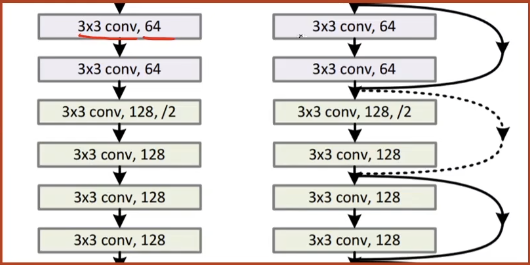
残差网络Resnet 随着神经网络层数的不断增加,在反向传播的过程中可能出现梯度爆炸或者梯度消失的情况
为什么会出现梯度消失或者梯度爆炸? 现在假设一个模型,其中连接层数为4层,反向传播(Backpropagation)用于计算每一层的权重 WWW 的梯度。这是通过链式法则计算的。假设神经网络的层数从1到4,每一层的输入、权重和激活函数可以定义如下
在计算离输入层较近的层的梯度时,会发现梯度的计算来源于上层的计算总和
链式法则是一个连乘的操作,在多次乘积操作后,最后一层的梯度可能趋近于零,也就是梯度消失,但若偏导数值大则会出现梯度爆炸的情况。
梯度消失/梯度爆炸的解决方法
梯度剪切:针对于梯度爆炸的情况,将梯度限制在一个限定的阈值内,如果更新梯度时梯度超过了阈值则将梯度改为阈值的边界,防止梯度过大的情况出现。
权重正则化:通过对权重做正则化来避免过拟合的情况出现,在梯度爆炸是权重的值可能会非常高,用正则化项来限制权重的大小,防止梯度爆炸的情况发生。
其中α为正则化项的系数
用Relu代替sigmoid作为激活函数:使用sigmoid函数作为激活函数时梯度值小于等于0.25,在连乘操作后显然会出现梯度消失或梯度爆炸的问题,但如果我们使用Relu函数作为激活函数,在对激活函数求导时,大于0的部分导数是恒等于1的,连乘不会出现梯度消失问题。
Batchnorm:通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。
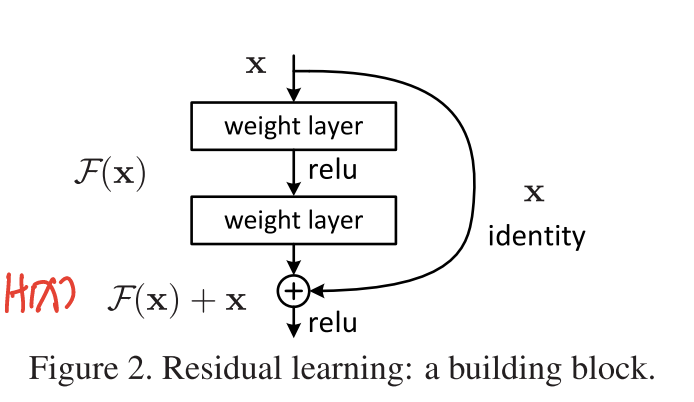
残差网络
残差网络如何解决梯度消失问题? 在原始的堆叠模型中,我们将需要的底层映射结果设为H(x),则H(x)=F(x)
但是在残差学习块中,我们假设需要的底层映射结果仍为H(x),在堆叠的非线性层我们让其训练另一个映射:F(x)=H(x)-x,则原始的底层映射结果改变为H(x)=F(x)+x,那么在上文的反向传播梯度计算中,公式可变为:
由此可见,连乘的因式有大于一的项,能够有效避免梯度消失问题。
如果还没有理解可以参考链接:http://www.atait.se.ritsumei.ac.jp/AIArc/WangZC/ResNet.pdf
模型实现及代码复现
与原始的堆叠模型不同的是,在堆叠块中添加跳连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class ResidualBlock (torch.nn.Module): def __init__ (self, channels ): super (ResidualBlock, self ).__init__() self .channels = channels self .conv1 = torch.nn.Conv2d(channels, channels, kernel_size=3 , padding=1 ) self .conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3 , padding=1 ) def forward (self, x ): y = F.relu(self .conv1(x)) y = self .conv2(y) return F.relu(x + y) class ResNet (torch.nn.Module): def __init__ (self ): super (ResNet, self ).__init__() self .conv1 = torch.nn.Conv2d(1 , 16 , kernel_size=5 ) self .conv2 = torch.nn.Conv2d(16 , 32 , kernel_size=5 ) self .mp = torch.nn.MaxPool2d(2 ) self .rblock1 = ResidualBlock(16 ) self .rblock2 = ResidualBlock(32 ) self .fc = torch.nn.Linear(512 , 10 ) def forward (self, x ): in_size = x.size(0 ) x = self .mp(F.relu(self .conv1)) x = self .rblock1(x) x = self .mp(F.relu((self .conv2))) x = self .rblock2(x) x = x.view(in_size, -1 ) return self .fc(x)