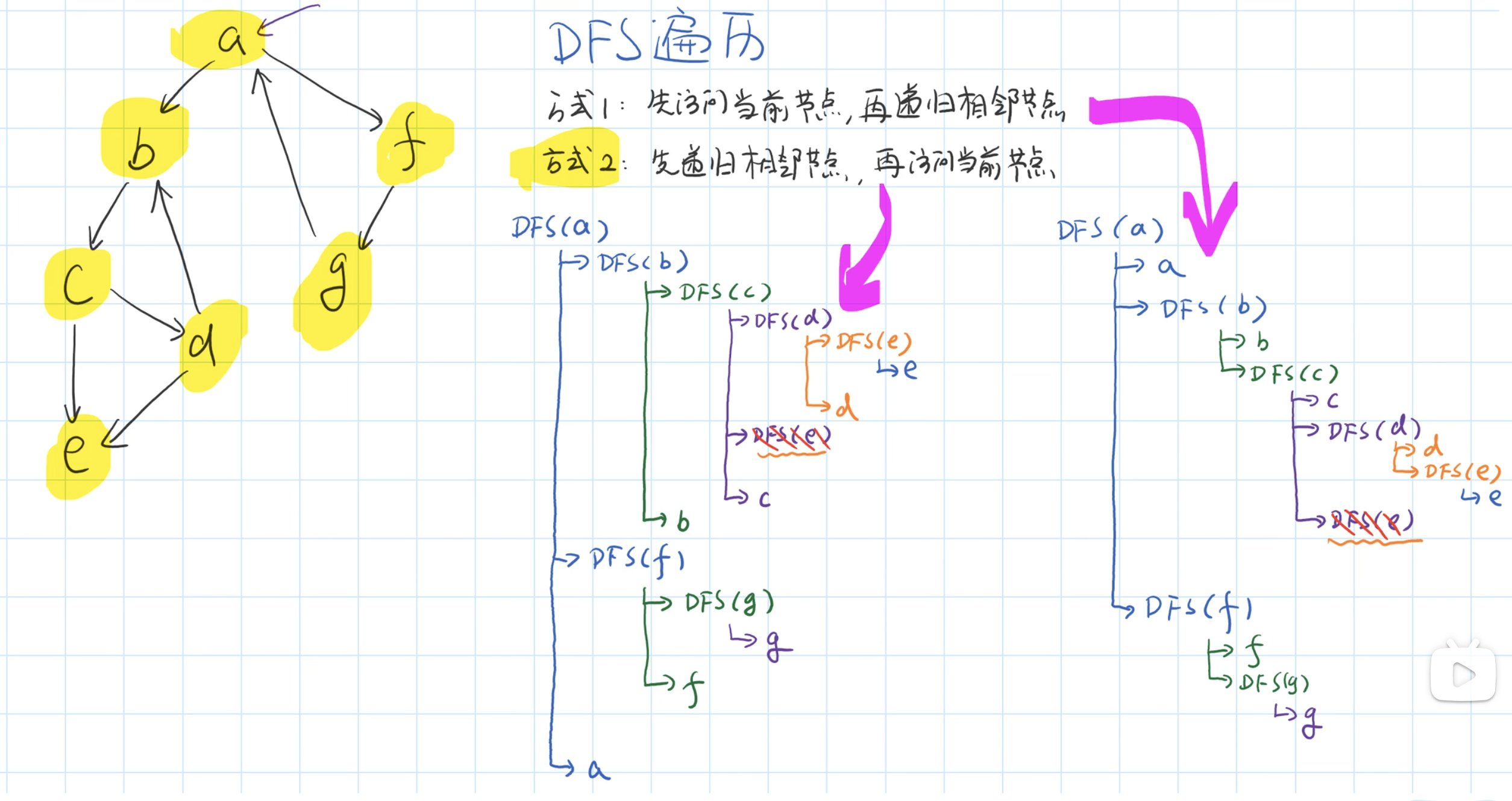
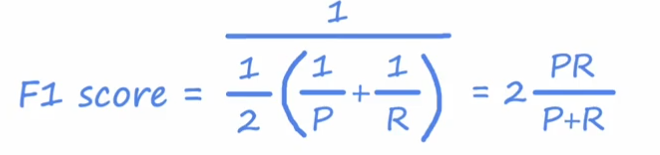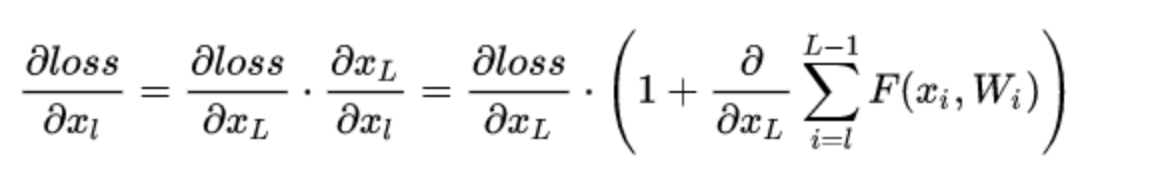MoCo
前置知识:什么是对比学习
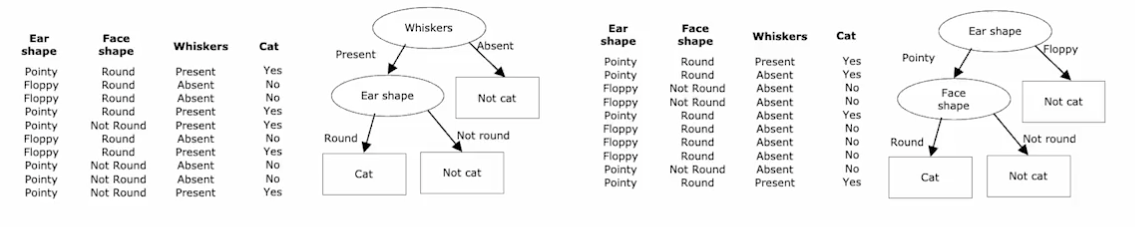
将三个图输入到一个神经网络中得到对应的特征向量f1、f2、f3。 在特征空间中f1,f2接近,f1,f3疏远(相似类别接近,不同类别疏远),如果不明白可以先看一下Embedding。为什么要说这个呢?以最左边的猫的图片为例,我们对其进行简单变换(平移、旋转等)得到两个新图(当然这两张图片还是猫!!没有变成狗!!对吧?),这两张新图对应的特征向量,在特征空间中接近,或者说相似度很高。生成新图,通过编码器将它们转化成Embedding向量,训练使,接近,, 疏远这个过程就是对比学习是无监督,可以看出这个编码器是很关键的,它没有因为图片的变动,而把它编码成狗。这可以作为一个pretext,当我们拥有的数据中不带标签的数据要远远大于带标签的数据的时候,我们可以用不带标签的数据进行对比学习的一个初始编码器,此编码器已经掌握了数据中的一部分特性,可以实现聚类功能,然后在用带标签数据进行微调。
- 数据增强
- 特征编码器
- MLP层
- 目标函数作用阶段,正样本是一个样本和增强样本,负样本是除此之外的所有样本
摘要
我们提出了用于无监督视觉表示学习的动量对比 (MoCo)。从对比学习[29]作为字典查找的角度来看,我们构建了一个带有队列和移动平均编码器的动态字典。这使我们能够动态构建一个庞大且一致的字典,以促进对比无监督学习。MoCo在ImageNet分类的通用线性协议下提供了具有竞争力的结果。更重要的是,MoCo学习的表示可以很好地转移到下游任务。在PASCAL VOC、COCO和其他数据集上的7个检测/分割任务中,MoCo可以优于其有监督的预训练对应物,有时大大超过了它。这表明无监督表示学习和监督表示学习之间的差距在许多视觉任务中很大程度上是接近的。
Introduce
在视觉领域,对比学习需要为样本生成字典,而encoder编码器的作用就是施行字典查找的角色,一个编码的序列应该和它对应的关键字相同而和其他的不同,这样的学习需要被表述为最小化对比损失,从这个角度来看我们应该建立符合以下条件的字典:
把字典维护成一个数据样本队列:将当前小批量数据的编码表示入队,最旧的数据表示则出队。
该队列将字典大小与小批量数据的大小解耦,从而使字典能够很大。、
由于字典中的键来自前面的几个小批量数据,提出使用一个缓慢更新的键编码器(它是通过查询编码器基于动量的滑动平均来实现的),以保持一致性。
自监督学习方法通常涉及两个方面:前置任务和损失函数
损失函数
Contrastive losses对比损失:
在表征空间中测量两个样本之间的相似性,不同于固定的类别标签,它的接近目标是不固定的,在训练期间目标会根据网络对数据的表征适时调整,例如在无监督学习的对比学习场景下,会从数据中选取不同样本,这些样本经过网络编码后形成的表征就用于动态确定对比损失中的目标。通过这种方式,对比损失能够更灵活地引导模型学习数据间的相似性和差异性,挖掘数据内在的特征表示。
Adversarial losses对抗损失:
衡量概率分布之间的差异
Pretext Tasks 前置任务
用于辅助模型学习数据特征的任务,虽然这些任务本身并非最终目的,但通过完成他们模型可以学到更有效的数据表示
- 恢复受损输入的任务:在受损的输入中恢复原始数据,比如去噪自动编码器,它以带有噪声的图像作为输入,目标是去除噪声,还原出原始清晰的图像,在这个过程中,模型学习到图像的特征和结构信息;上下文自动编码器则是通过利用图像的上下文信息来恢复输入,在恢复过程中让模型理解图像不同部分之间的关系;跨通道自动编码器(如彩色化任务),以灰度图像为输入,生成对应的彩色图像,帮助模型学习颜色信息与图像内容之间的关联。
- 生成伪标签的任务:通过对数据进行特定操作来生成伪标签,以此引导模型学习。对单个(“示例”)图像进行变换,根据变换前后的关系生成伪标签,让模型学习到图像在不同变换下的不变性特征;
Method
把对比学习当做字典查找方法
在对比学习的场景下,我们考虑这样一种情况:有一个经过编码的查询向量q,以及一组同样经过编码的样本k0,k1,k2,…,这些样本充当字典中的键。假设在这组键中,只有一个键(记为k+ )与查询向量q匹配。
在衡量查询向量q和其他的键的相似度时使用对比损失函数InfoNCE
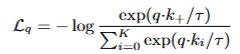
在无监督学习场景下,没有像监督学习那样预先标注好的类别标签,对比损失发挥着关键作用。它通过鼓励编码器网络将来自同一实例的查询(query)和键(key)映射到相似的特征空间,同时将来自不同实例的查询和键映射到不同的特征空间,以此来训练编码器网络。这样,编码器网络就能学习到数据的有效特征表示,为后续任务(如分类、检测等)奠定基础。
动量对比
从上述角度来看,对比学习是一种在图像等高维连续输入上构建离散字典的方法。这里所说的字典具有动态性,体现在两个方面:其一,字典中的键是随机采样得到的;其二,在训练过程中,用于编码这些键的编码器也在不断变化。我们提出这样一个假设:一个能够涵盖丰富负样本的大字典有助于学习到良好的特征,并且在训练过程中,尽管字典键的编码器会不断变化,但应尽可能保持其一致性。基于这一动机,将介绍动量对比(Momentum Contrast,MoCo)方法。
将字典维护成一个数据样本队列。在之前的方法中对比学习常常被视为在高维连续输入上构建离散字典的过程,以往的方法在构建字典时字典大小往往受限于小批量数据的大小,而当把字典当成一个队列时,当前小批量数据的编码表示会被添加到队列中,同时最旧的小批量数据的编码表示会从队列中移除,这种方法会使得字典可以积累多个小批量数据的信息。
动量更新
使用队列可以使字典变大,但同时也会导致反向传播更新key编码器变得棘手
最简单的解决方法是将从查询编码器复制键编码器,忽略梯度问题,但效果不佳
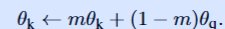
在更新中,只有查询编码器的参数根据反向传播来更新,而键编码器的参数根据动量更新公式来进行调整
其中m接近1,则证明键编码器的参数很大程度上会保留原有的信息,只有少部分被查询编码器更新
实验发现,相对较大的动量值(如默认的(m = 0.999) )比小动量值(如(m = 0.9) )效果好得多。这表明在利用队列进行字典构建和对比学习时,让键编码器缓慢演变是核心要点。缓慢演变的键编码器能够更好地维护队列中键表示的一致性,从而提升模型在无监督视觉表征学习任务中的性能。如果动量值较小,键编码器变化相对较快,就难以保证不同小批量数据编码得到的键之间的一致性,导致模型性能下降。
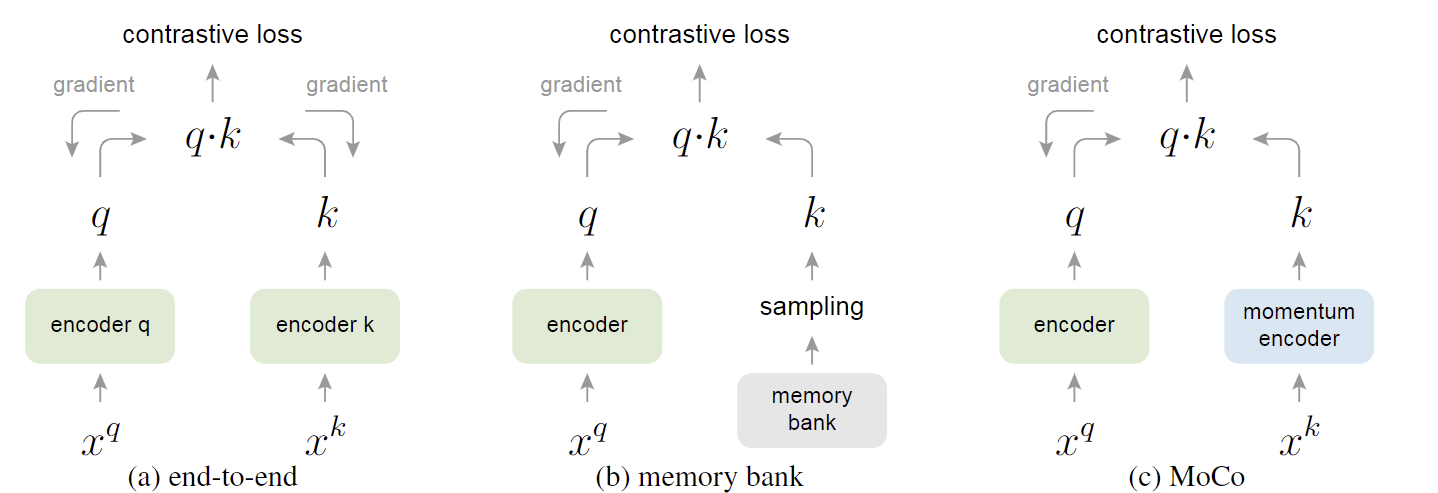
三种不同的更新策略:
- 端到端:字典大小与mini-batch size严格相关,受限于GPU显存
- 记忆库:库中信息的更新不符合一致性
- MoCo
前置任务
正负样本:如果来自同一张图片的增强样本,则就是正样本对,否则是负样本对
分别用编码器(f_{q})和(f_{k})对同一图像的不同增强 “视图” 进行编码,并通过对比损失优化编码器参数。如果 q 和 k 来自不同图像,对比损失的优化方向可能会偏离学习同一图像不同特征表示相似性的目标,导致模型难以准确学习到图像的有效特征表示。在文中所采用的方法里,会对同一幅图像进行随机数据增强操作,产生两个不同的随机 “视图”,一个 “视图” 用于生成 q,另一个 “视图” 用于生成 k。

技术细节
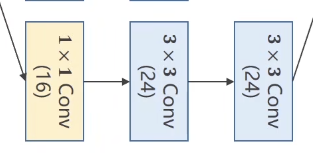
采用resnet作为编码器,在全局平均池化后其最后一个全连接层会输出固定维度128的向量,在输出向量后会根据L2范数进行归一化处理,处理后的向量就作为查询或者键的表征。loss函数中的温度超参数 τ 设置为 0.07(参照文献 [61]) 。数据增强的设置:从随机调整大小后的图像中裁剪出 224×224 像素的区域,接着对其进行随机颜色抖动、随机水平翻转以及随机灰度转换操作,这些操作都可通过 PyTorch 的 torchvision 工具包来实现。
单纯的使用BN会让学习表征的效果变差,所以突出新的BN策略
shuffling BN:
在训练时,使用对个GPU,对每个GPU上的样本独立进行BN操作,对于键编码器,在将当前小批量样本分配到各个GPU之前,打乱样本顺序,而查询编码器的小批量样本顺序则保持不变,这样做可以确保用于计算查询和其正样本键的批量统计信息来自两个不同的子集。
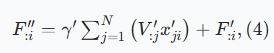

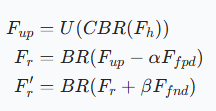
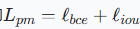 对于聚焦模块,结合了加权二元交叉熵函数和加权交并比损失函数
对于聚焦模块,结合了加权二元交叉熵函数和加权交并比损失函数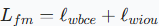 促使聚焦模块更加关注可能存在的干扰区域
促使聚焦模块更加关注可能存在的干扰区域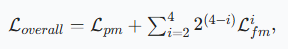
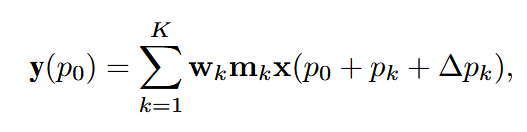










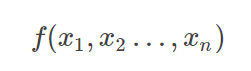
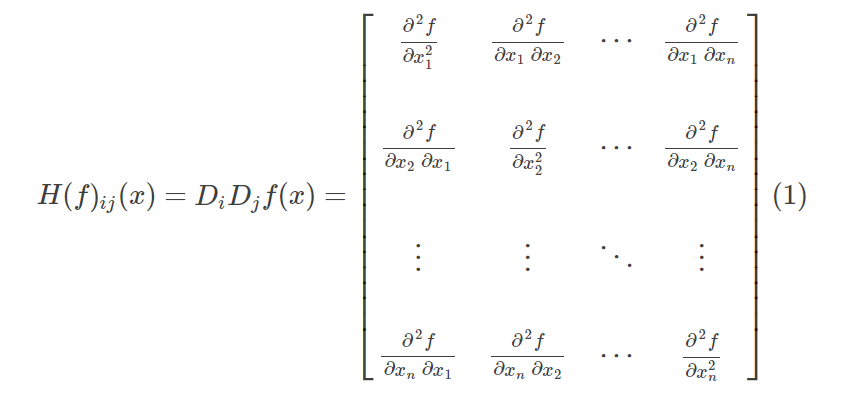
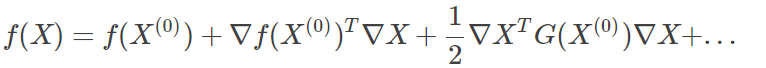
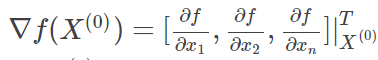 是函数在X0点的梯度,G(X0)就是海森矩阵。
是函数在X0点的梯度,G(X0)就是海森矩阵。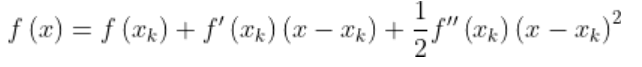
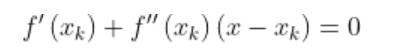
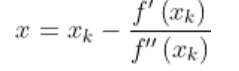
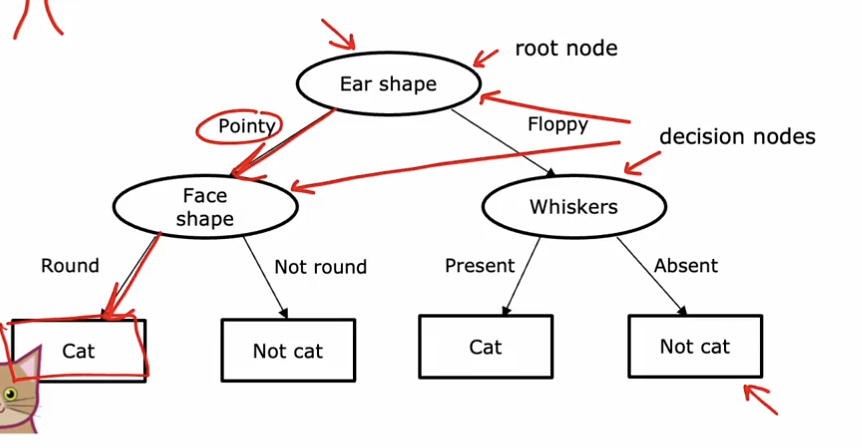
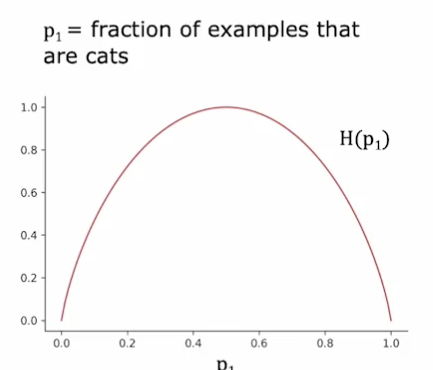

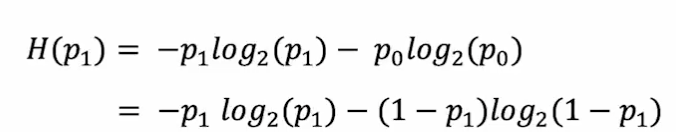
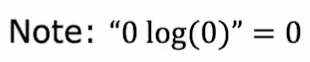
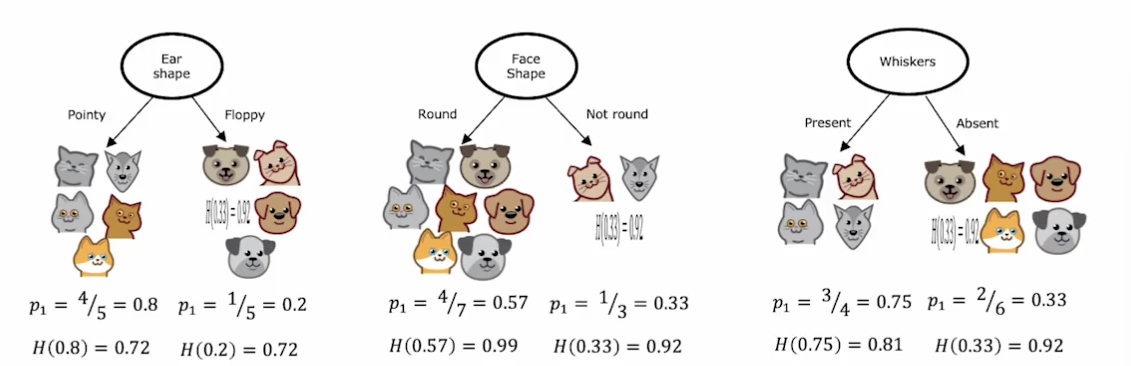
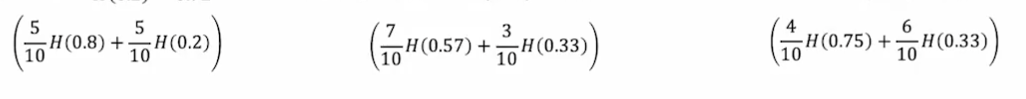
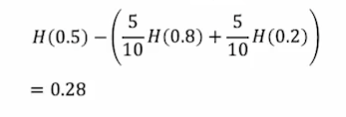

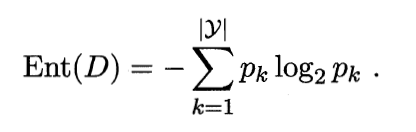 信息熵的计算公式
信息熵的计算公式
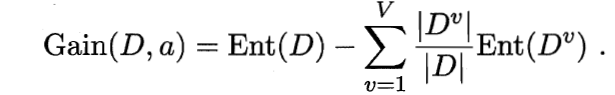
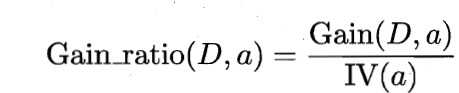
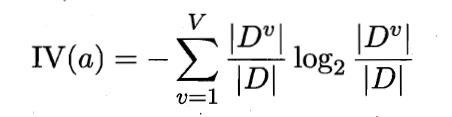 为属性a的固有值
为属性a的固有值